# Introduction
This is a weakly supervised ASR recipe for the LibriSpeech (clean 100 hours) dataset. We training a
conformer model using BTC/OTC with transcripts with synthetic errors. In this README, we will describe
the task and the BTC/OTC training process.
## Task
We propose BTC/OTC to directly train an ASR system leveraging weak supervision, i.e., speech with non-verbatim transcripts.
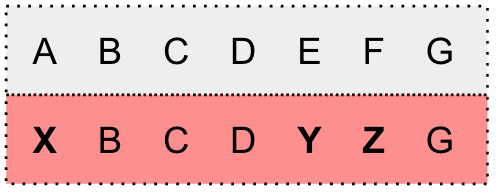
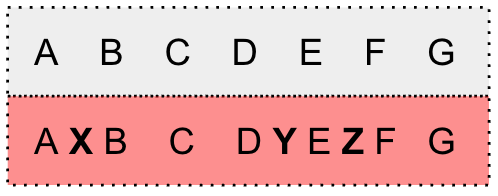
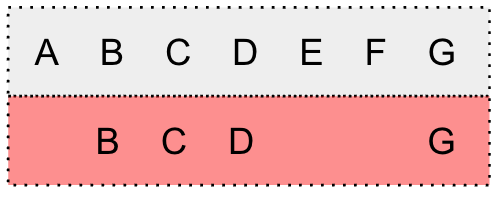
Substitution errorInsertion errorDeletion error
Examples of error in the transcript. The grey box is the verbatim transcript and the red box is the inaccurate transcript. Inaccurate words are marked in bold.
This is achieved by using a special token $\star$ to model uncertainties (i.e., substitution errors, insertion errors, and deletion errors)
within the WFST framework during training.\
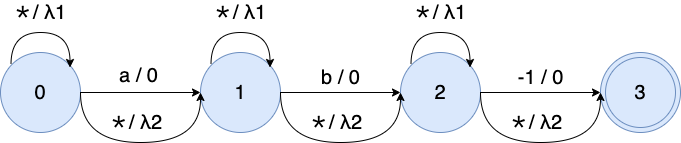
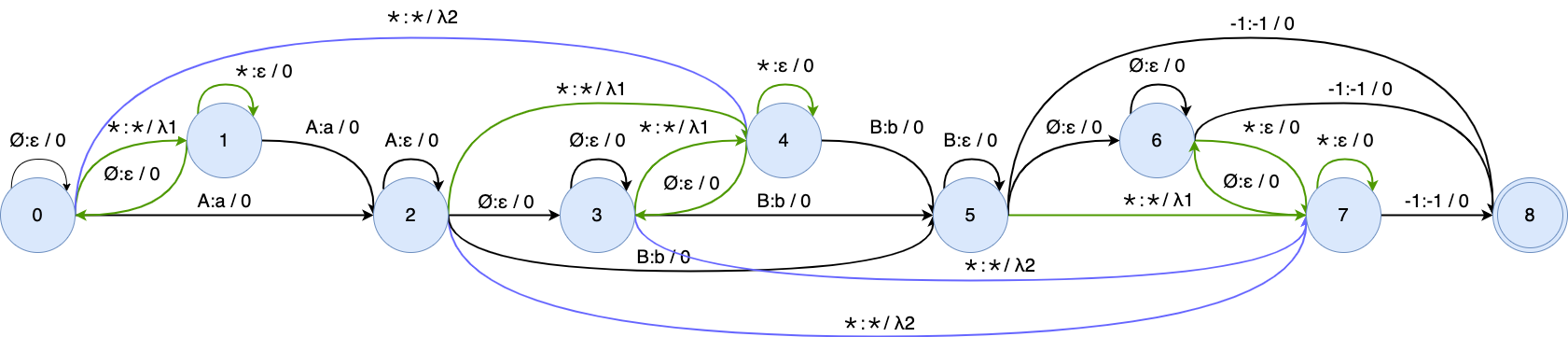
we modify $G(\mathbf{y})$ by adding self-loop arcs into each state and bypass arcs into each arc.
OTC WFST representations of the transcript "a b"
After composing the modified WFST $G_{\text{otc}}(\mathbf{y})$ with $L$ and $T$, the OTC training graph is shown in this figure:
OTC training graph. The self-loop arcs and bypass arcs are highlighted in green and blue, respectively.
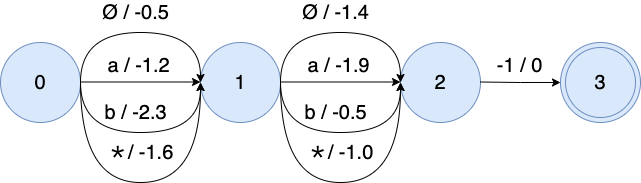
The $\star$ is represented as the average probability of all non-blank tokens.
OTC emission WFST
The weight of $\star$ is the log average probability of "a" and "b": $\log \frac{e^{-1.2} + e^{-2.3}}{2} = -1.6$ and $\log \frac{e^{-1.9} + e^{-0.5}}{2} = -1.0$ for 2 frames.
## Description of the recipe